Un mémo sur la mise en place d’un cluster en haute disponibilité d’hyperviseurs Proxmox avec un stockage distribuée et redondant Ceph. Cet article traite uniquement de l’installation et de la configuration de Ceph avec Proxmox.
Update -> https://memo-linux.com/proxmox-8-cluster-ha-ceph/
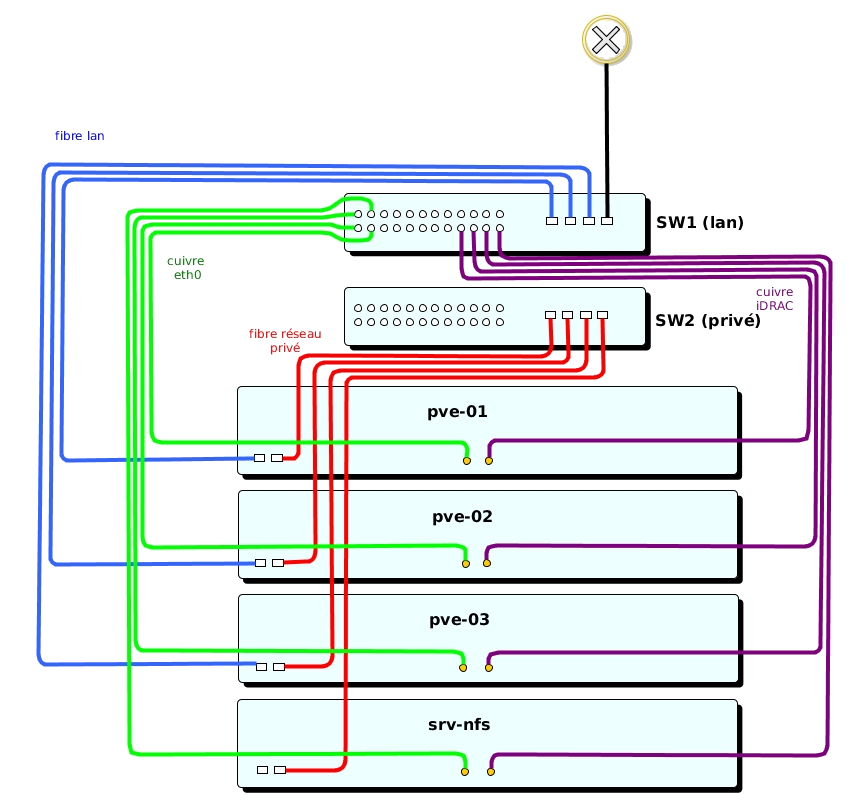
Présentation du cluster Proxmox HA avec Ceph
Le cluster Ceph est composé de 3 nœuds Proxmox et un serveur NFS pour la sauvegarde des VM et le stockage des ISO.
Chaque serveur Proxmox utilise 4 interfaces réseau :
- cuivre eth0 : port d’administration du serveur
- fibre LAN : plage d’adresse dédiée aux serveurs sur le site d’installation
- fibre réseau privé : dédiée aux communications entre les serveurs (pour le fonctionnement du cluster, et pour le fonctionnement de Ceph)
- cuivre pour la carte iDRAC
L’installation du cluster nécessite au minimum 2 switches munis de ports fibre et de ports cuivre, respectivement dédiés aux communications sur le LAN et aux communications privées entre serveurs.
Schéma de principe du cluster Proxmox
Installation de Promox
Installer Proxmox sur les trois nœuds du cluster, voir cet article : Proxmox 5 : Installation
Après l’installation, il est possible d’utiliser le script de post installation pour simplifier la configuration générale des Proxmox : https://memo-linux.com/proxmox-script-post-installation/
Configuration des interfaces réseaux des Proxmox
- Pour chaque serveur, se connecter au serveur avec un navigateur internet en utilisant l’adresse configurée lors de l’installation : https://pve.domaine.tld:8006
- Après avoir forcé l’acceptation du certificat, l’interface Proxmox s’affiche et saisir les identifiants. La case « save user name » permet de mémoriser le user name (ici root) de manière à ne devoir saisir que le mot de passe lors de la prochaine connexion :
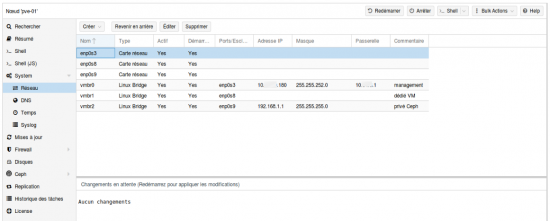
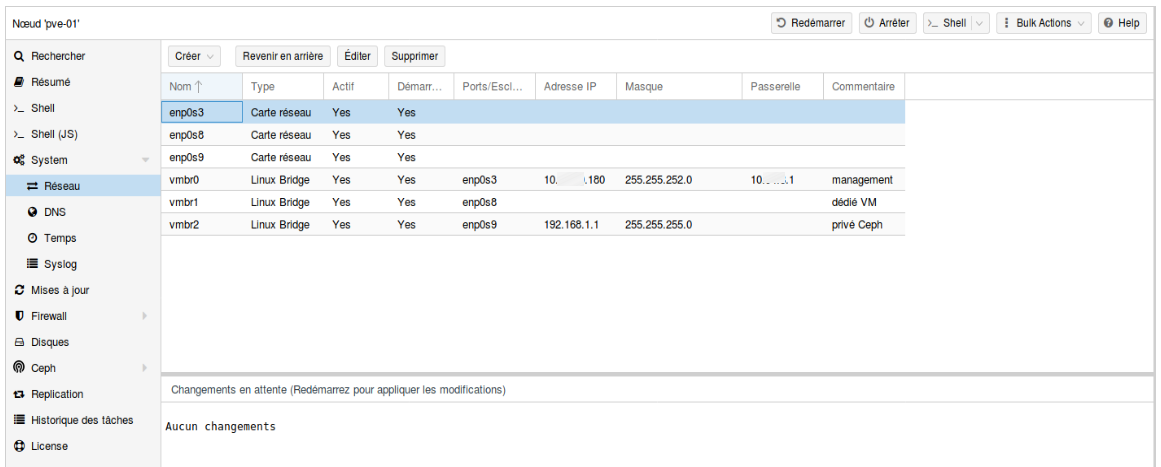
- Configurer les interfaces réseau sur chaque serveur Proxmox avec :
- vmbr0 : Interface cuivre de management avec l’IP du serveur (créé à l’installation)
- vmbr1 : Interface fibre sans adresses réseau, dédiée aux VM pour accès au LAN
- vmbr2 : Interface fibre avec adresse réseau privé, dédiée à la communication entre les nœuds

Mise en cluster des 3 nœuds Proxmox
- Sur chaque serveur Proxmox ajouter ces 3 lignes dans
/etc/hosts:- 192.168.1.1 cluster-01
- 192.168.1.2 cluster-02
- 192.168.1.3 cluster-03
- Vérifier que les serveurs sont synchroniser avec un serveur de temps :
timedatectl
- Sur pve-01, créer le nom du cluster sur le réseau privé :
pvecm create kluster -bindnet0_addr 192.168.1.0 -ring0_addr cluster-01
pvecm add cluster-01 -ring0_addr 192.168.1.2
pvecm add cluster-01 -ring0_addr 192.168.1.3
Installation de Ceph sur les 3 nœuds Proxmox
- Installater de Ceph sur chaque nœud Proxmox :
https_proxy=http://IP_Proxy:PORT pveceph install -version luminous
Cette commande doit être exécutée sur chaque serveur. Elle permet de télécharger et d’installer Ceph en étant derrière un proxy.
pveceph init --network 192.168.1.0/24
pveceph createmon
Vérification des disques pour Ceph
- Sur le premier nœud Proxmox, sélectionner le menu Disques :
- Se positionner sur chaque disque non-système et l’initialiser en cliquant sur le bouton « Initialize Disk with GPT »
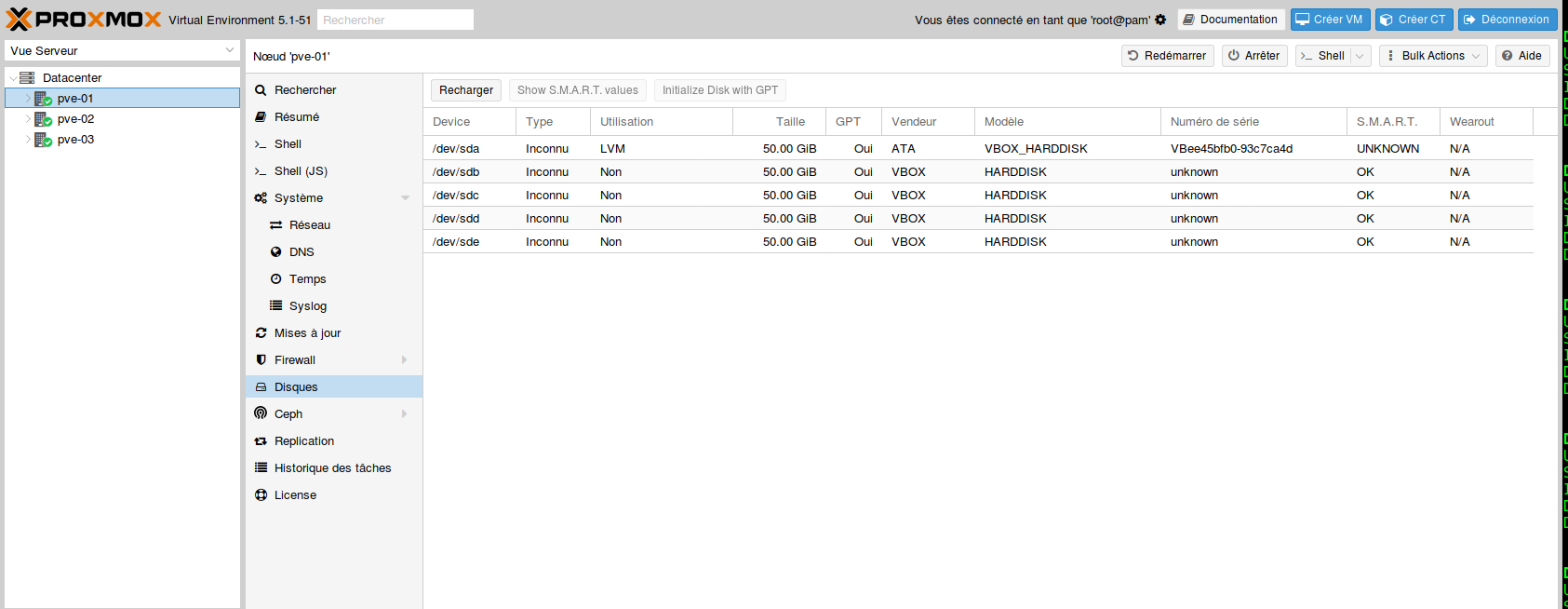
Dans ce menu, apparaît tous les disques présent sur le serveur. Le disque système (ici sur /dev/sda) se différencie des 4 autres.
Cette opération est à réitérer sur chaque serveur.
Configurer Ceph sous Proxmox
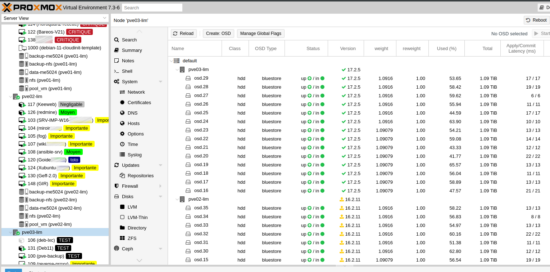
Sous Proxmox, la configuration du Ceph est très simplifiée et assistée. Cette opération de configuration passe par deux étapes : création des OSD et création du pool.
De façon très simple et schématique, les OSD sont les disques qui constituent le volume disque dédié au Ceph, où sera écrit les données (ici les données sont les VM). Le pool définit les règles de réplications des données sur l’ensemble des OSD.
Création des OSD
- Sélectionner le premier nœud Proxmox, puis menu Ceph -> OSD et cliquer sur « Create:OSD » :
- Sélectionner le premier disque comme OSD et journal :
- Faire de même avec les autres disques sauf pour le journal qui reste seulement sur le premier disque (/dev/sdb) :
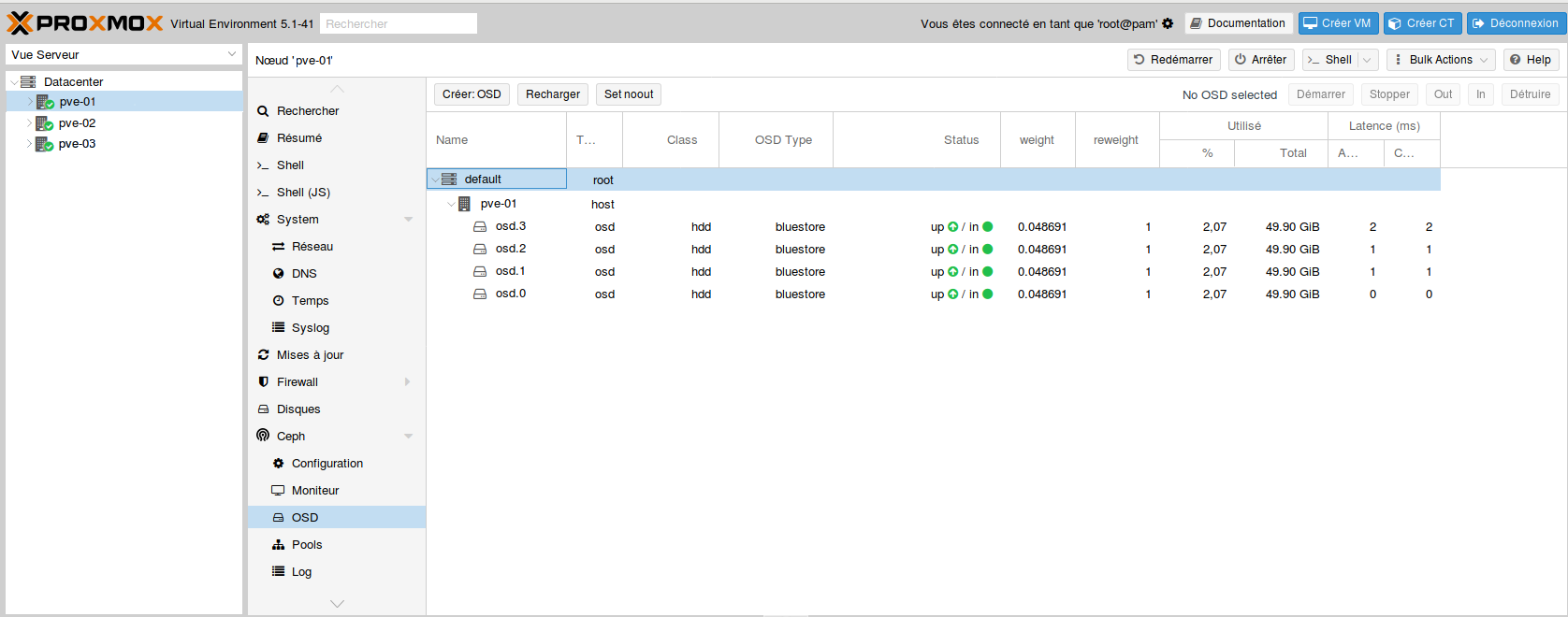
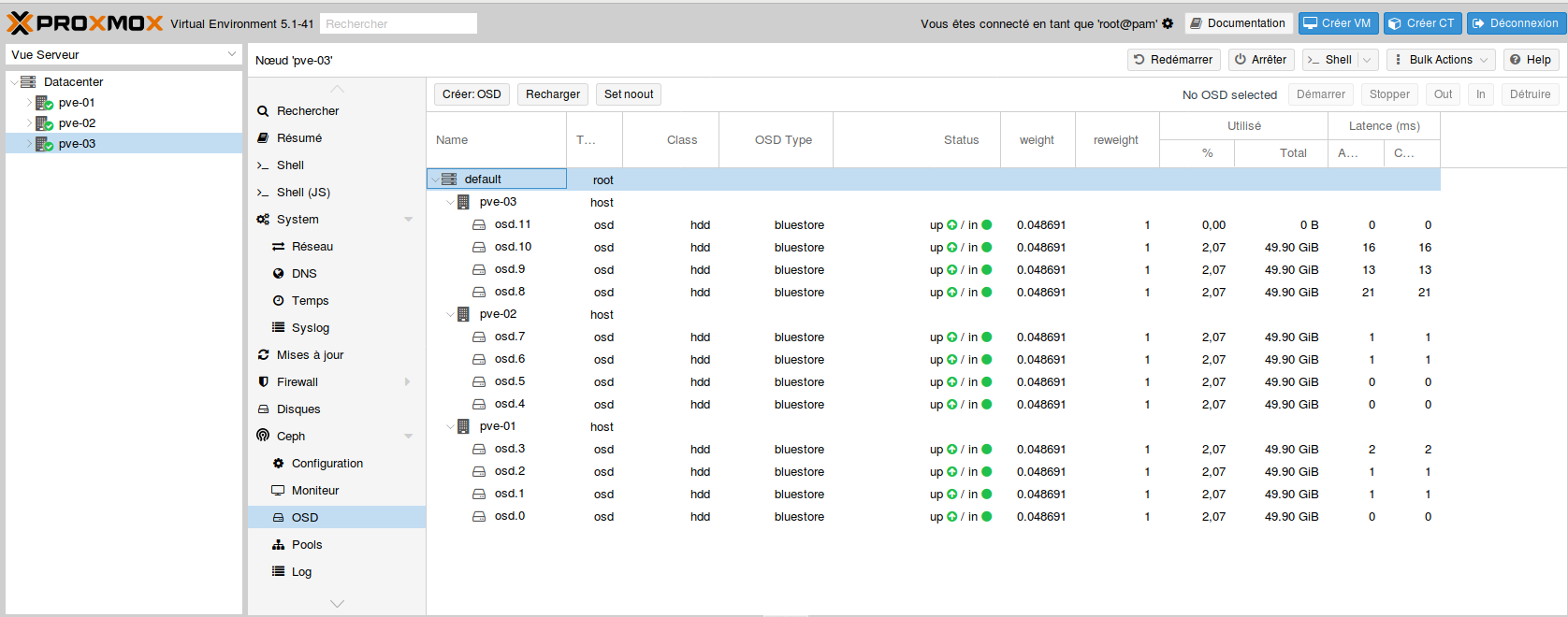
- Tous les OSD créés sur le premier nœud :
- Refaire les mêmes actions sur les autres nœuds afin d’obtenir ce résultat :
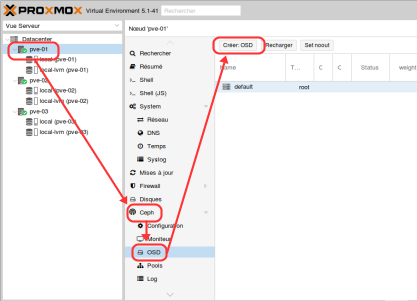
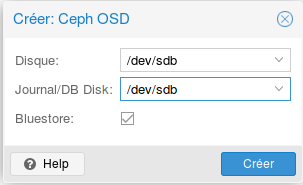
BlueStore est un nouvel algorithme de stockage pour Ceph. Il prétend offrir de meilleures performances : en gros 2x en écriture, contrôle checksum global sur la data, et compression-à la volée.
Remarque concernant le journal : si possible, il est préférable de dédier le journal uniquement un disque de type SSD, pour des raisons de performances.
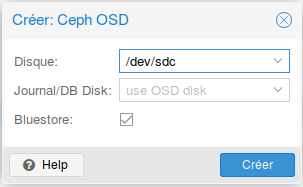
Création du pool
Avant de créer le nouveau pool, il faut calculer le pg_num.
- Calcul du pg_num :
(OSDx100)/size -> choisir la puissance de 2 supérieur au résultat de l’opération.- OSD : nombre total d’OSD choisi pour le pool
- size : nombre de réplication
- Exemple pour le nouveau pool : (12*100)/3 = 400
- pg_num sera la puissance de 2 supérieure à 400, c’est à dire 512
- Exemple pour le nouveau pool : (12*100)/3 = 400
- Aller dans le menu « Ceph » puis « Pools » et cliquer sur « Créer » :
- Remplir les champs :
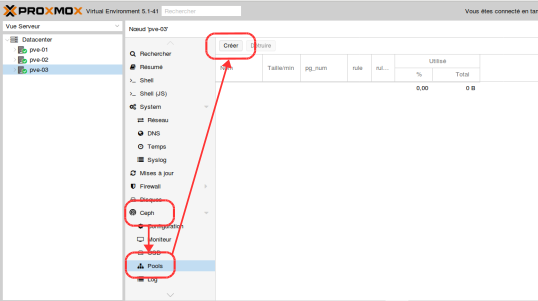

Le nouveau pool est créé, et en ayant laissé coché la case Add Storages, deux stockages pool_vm_vm et pool_vm_ct sont ajouté automatiquement (rubrique Datacenter / stockage)
Il s’agit là de stockages partagés : l’un réservé à des conteneurs LXC l’autre à des images disque KVM.

Les deux stockages apparaissent sur tous les nœuds du cluster.
Configuration du minuteur Watchdog matériel
Sous Proxmox 5, il n’est plus nécessaire de configurer le fencing car il est pris en charge directement par le système.
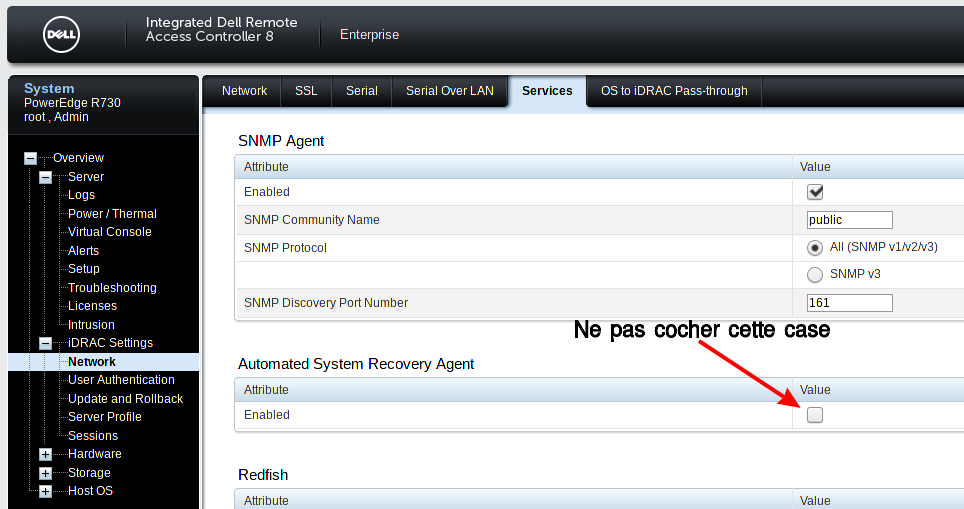
Cependant, il est possible de configurer le watchdog matériel et de régler la durée à 10s. Ce qui qui suit est valable pour les serveurs Dell possédant la carte iDrac.
Vérification des valeurs actuelles du Watchdog- Installer l’utilitaire dracadm7 :
apt install srvadmin-idracadm7
idracadm7 getsysinfo -w
- Résultat :
Watchdog Information: Recovery Action = None Present countdown value = 479 seconds Initial countdown value = 480 seconds
Les valeurs par défaut sont trop hautes et aucune action n’est définie.
Configuration du Watchdog à 10secondes
- Modifier le fichier
/etc/default/pve-ha-manager/pour activer watchdog avec le moduleipmi_watchdog:
sed -i '2 s/#//' /etc/default/pve-ha-manager
ipmi_watchdog :echo "options ipmi_watchdog action=power_cycle panic_wdt_timeout=10" > /etc/modprobe.d/ipmi_watchdog.conf
- action : comportement du serveur lors d’un problème
- panic_wdt_timeou : choix de la durée en seconde avant action lors d’un problème
- Ajouter l’option
nmi_watchdog=0pourGRUB_CMDLINE_LINUX_DEFAULT:
sed -i '/^GRUB_CMDLINE_LINUX_DEFAULT=/s/"quiet"/"quiet nmi_watchdog=0"/' /etc/default/grub
update-grub
/opt/dell/srvadmin/sbin/dcecfg command=removepopalias aliasname=dcifru
reboot
idracadm7 getsysinfo -w
- Résultat :
Watchdog Information:
Recovery Action = Reboot
Present countdown value = 9 seconds
Initial countdown value = 10 seconds
Tuning Proxmox
- Rendre plus rapide la migration des VM : https://memo-linux.com/proxmox-booster-la-migration-des-vm/
Bonjour,
Je trouve très inintéressant votre tutoriel et très explicite.
Merci de l’avoir partagé mais j’ai une question.
Comment mettre en place une réplication sur proxmox 5 car en essayant de la créer j’ai ce message d’erreur.:
missing replicate feature on volume ‘local-lvm:vm-100-disk-1’ (500
cordialement,
Bonjour exinvil,
la réplication fera l’objet d’un futur article car dans le cas de la HA pas besoin de réplication. En gros pour mettre en place la réplication, il faut une partition ZFS…
Bonsoir,
Je viens de faire le même labo avec 3 proxmox 5.2 dans virtualbox.
J’ai également activé le HA, mais je n’ai pas activé le watchdog matériel car je ne travaille qu’avec supermicro et je n’ai pas encore cherché comment faire. (et puis pour mes tests en virtualbox, c’est inutile :D)
J’arrive à offline-migrer un container LXC d’un serveur à l’autre avec une panne d’environ 20 secondes, mais si j’éteins le proxmox qui héberge le container, HA tente de le monter sur un autre proxmox mais il n’y arrive pas:
voici l’erreur:
task started by HA resource agent
Job for pve-container@500.service failed because a timeout was exceeded.
See « systemctl status pve-container@500.service » and « journalctl -xe » for details.
TASK ERROR: command ‘systemctl start pve-container@500’ failed: exit code 1
est-ce que ceph n’est pas censé répliquer les données du pool sur tous les OSD ?
Salut fred,
Merci pour ton tuto, super, come d’hab ;)
Tu utilise quoi comme serveur de partage ? Et pourquoi ?
FreeNAS est pas mal, mais compliqué au niveau du controleur raid.
Merci
Salut Damien
un simple serveur NFS sous Debian :-)
Ca marche, merci de l’info ^^
Salut Fred,
Dans ton exemple, tu as 4 disques par machine, mais au final que 2 « stockages »
Tes 3×4 disques sont donc assemblés pour ne former que 2 « stockages » ?
Je te demande car il est indiqué sur la doc de proxmox que le raid materiel (hba) n’est pas compatible avec Ceph.
Si Ceph assemble les disques comme un raid software, je comprend.
Sinon je ne comprends pas trop.
De plus, le raid materiel n’est pas compatible avec le stockage repliqué (meme doc), mais ça je le comprend car il faut du zfs, comme expliqué dans ton article sur le stockage répliqué.
Merci de ton aide :)
Petite coquille :
———-
Je te demande car il est indiqué sur la doc de proxmox que le raid materiel n’est pas compatible avec Ceph.
———-
Par HBA j’entendais carte pci pour gerer le stockage, mais apparement : carte RAID materiel =/= carte HBA (mode passthrough pour faire du raid software)
Désolé
Bonjour a vous ; super tuto
Voila j’aimerais vous posez deux trois question concernant un projet de déploiement , est-ce possible
Bonjour,
si je peux aider pourquoi pas mais je n’ai plus beaucoup de temps
Bonjour,
est ce que c’est possible de faire HA avec seulement deux nœuds ?
j’ai deux serveurs super-micro, je vais migrer des VMs dedans, est ce que ya une possibilité de faire la HA avec deux serveurs?
Bonjour,
pas possible de faire de la HA avec seulement 2 noeuds…
Bonjour Fred
J’ai besoin d’un conseil.
J’ai 3 noeuds avec chacun 4 interfaces réseau.
2 pour les vms
J’ai lu qu’il est préférable de séparer le réseau pour le cluster proxmox (corosync) et le réseau ceph.
Ce qui n’est pas le cas chez moi, ce qui marche plus tôt pas mal .
Pour optimiser ça, que me conseil tu, agréger 2 interface et continuer avec ceph et corosync sur le même réseau ou corosync sur une interface et ceph sur l’autre.
J’espère que je fait comprendre.
Par avance merci et encore félicitations pour tes tutos c’est ma bible
Bonjour Alexis,
une interface réseau par fonction, c’est fortement recommandé. Dans un premiers temps tu peux mettre sur le même réseau et ça va fonctionner mais quand tu commences à avoir pas mal de VM les ennuis vont commencer. Le CEPH c’est consommateur de ressources et le corosync a besoin d’une latence très basse. Donc le mieux est de séparer les réseaux (si pas de switch, tu peux le faire en topologie MESH)
Bonjour à vous.
Votre présentation et claire et efficace ca fait plaisir.
J’ai par contre un petit souci concernant ce procédé.
J’ai 3 noeuds en cluster classique fonctionnel depuis quelques semestres :)
J’ai voulu passer à la HA avec CEPH. Cependant lors du processus d’installation (que je réalise en modee clickodrome) je me prend assez rapidement après l’étape « Reloading API to load new Ceph RADOS library » un « got timeout (500) » ne me proposant pas l’étape suivante qui est le choix du réseau et interface dédiée au CEPH.
J’ai lu des choses au sujet de MTU à 9000 qui pouvait poser problème mais je suis en 1500 classique là encore…
Avez-vous déjà rencontré ce type de soucis?