Un mémo sur la mise en place d’un cluster haute disponibilité d’hyperviseurs Proxmox avec un stockage distribuée et redondant Ceph.
Cet article traite uniquement de l’installation et de la configuration de Ceph avec Proxmox pour avoir un stockage partagé entre les nœuds.
Pour Proxmox 5 voir cet article : https://memo-linux.com/proxmox-5-mise-en-place-dun-cluster-ha-avec-ceph/
Cet article traite de deux méthodes pour la configuration du Ceph :
- Méthode simple car géré automatiquement par Proxmox avec un seul pool
- Méthode plus complexe car géré à la main mais attention, car la gestion du Ceph ne pourra plus s’administrer à travers l’interface web de Proxmox.
L’installation de Proxmox 4.x est identique à la version 3.x : tuto installation Proxmox 3.x
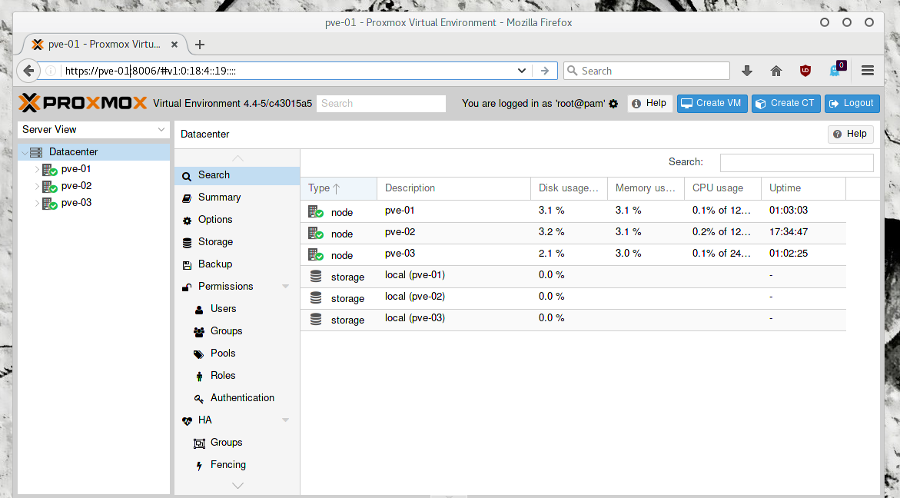
Présentation de mon cluster Proxmox :
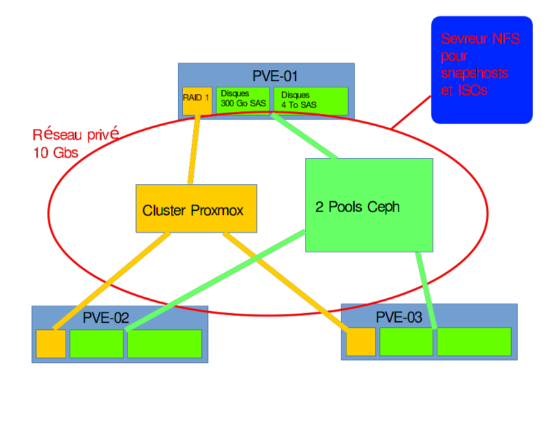
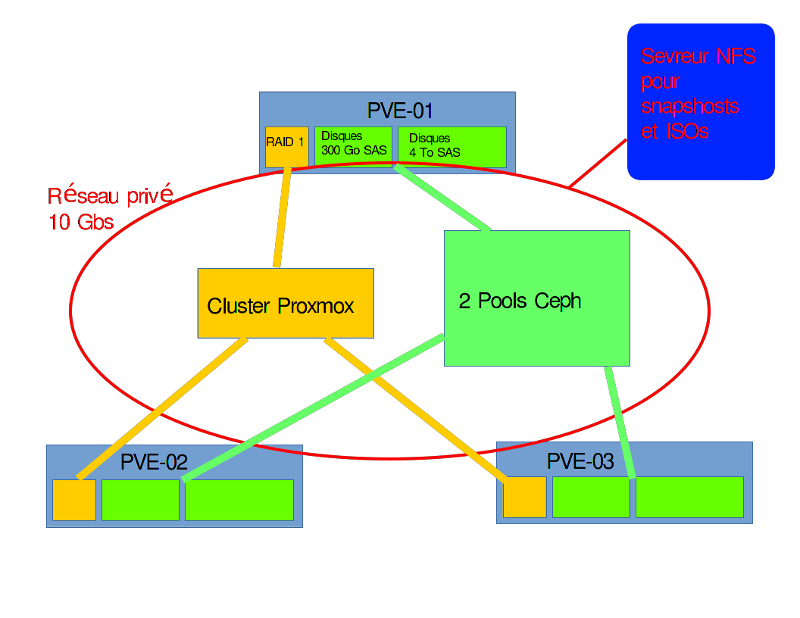
Mon cluster Ceph sera composé de 3 nœuds Proxmox et 1 serveur NFS pour les snapshots des VM et le stockage des ISOs.
Les machines virtuelles seront réparties sur les 3 noeuds Proxmox.
Dans cet article, je ne traite pas des sauvegardes des VMs.
Partie réseau :
- LAN réseau entreprise : 10.10.8.0/24
- LAN privée : 192.168.1.0/24
- Les interfaces réseaux :
- Vmbr0 : interface administration des proxmox en port cuivre
- Vmbr1 : interface réseau sur le LAN réseau entreprise en port fibre, cette interface sera configurée pour le réseau des VMs
- Vmbr2 : interface réseau sur le LAN privé en port fibre, cette interface sera utilisée pour le cluster et Ceph
- Adresses réseaux :
- cluster-01 :
- vmbr0 10.10.8.202
- vmbr2 192.168.1.1
- cluster-02 :
- vmbr0 10.10.8.204
- vmbr2 192.168.1.2
- cluster-03 :
- vmbr0 10.10.8.206
- vmbr2 192.168.1.3
- cluster-01 :
Mise en cluster des 3 nœuds Proxmox
Avant de parler de Ceph, il faut mettre les 3 nœuds Proxmox en cluster.
- Sur tous les noeuds, ajouter ces informations dans
/etc/hosts:- 192.168.1.1 cluster-01
- 192.168.1.2 cluster-02
- 192.168.1.3 cluster-03
- Vérifier que les serveurs sont synchroniser avec un serveur de temps :
timedatectl
pvecm create kluster -bindnet0_addr 192.168.1.0 -ring0_addr cluster-01
pvecm add cluster-01 -ring0_addr 192.168.1.2
pvecm add cluster-01 -ring0_addr 192.168.1.3
Installation de Ceph sur les 3 nœuds Proxmox
- Installation de Ceph sur chaque nœud Proxmox :
https_proxy=http://IP_Proxy:PORT pveceph install -version jewel
pveceph init --network 192.168.1.0/24
pveceph createmon
Cluster Ceph gérer entièrement par Proxmox
Présentation de mon cluster Proxmox :
- 3 Serveurs Dell R730 pour les Proxmox, avec :
- 2 disques 146 Go SAS 15K RAID1 pour PVE + Monitor
- 4 disques 4 TO SATA 7.4K pour OSD
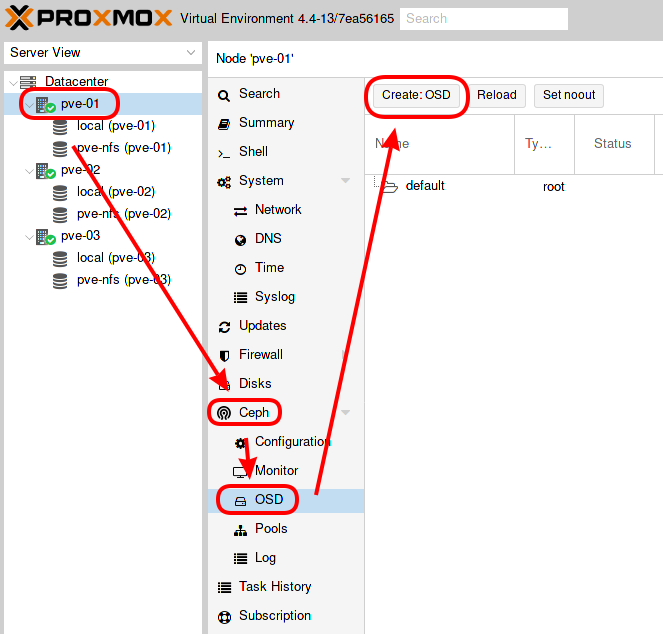
a/ Création des OSD
- Sélectionner le premier nœud proxmox, puis menu Ceph -> OSD et cliquer sur « Create:OSD » :
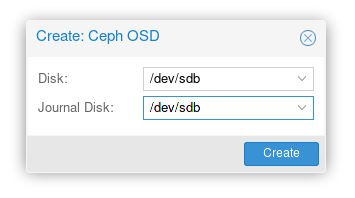
- Sélectionner le premier disque comme OSD et journal :
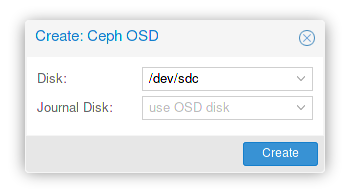
- Faire de même avec les autres disques sauf pour le journal qui reste seulement sur le premier disque :
- Tous les OSDs créés sur le premier nœud :
- Refaire les mêmes actions sur les autres nœuds afin d’obtenir ce résultat :

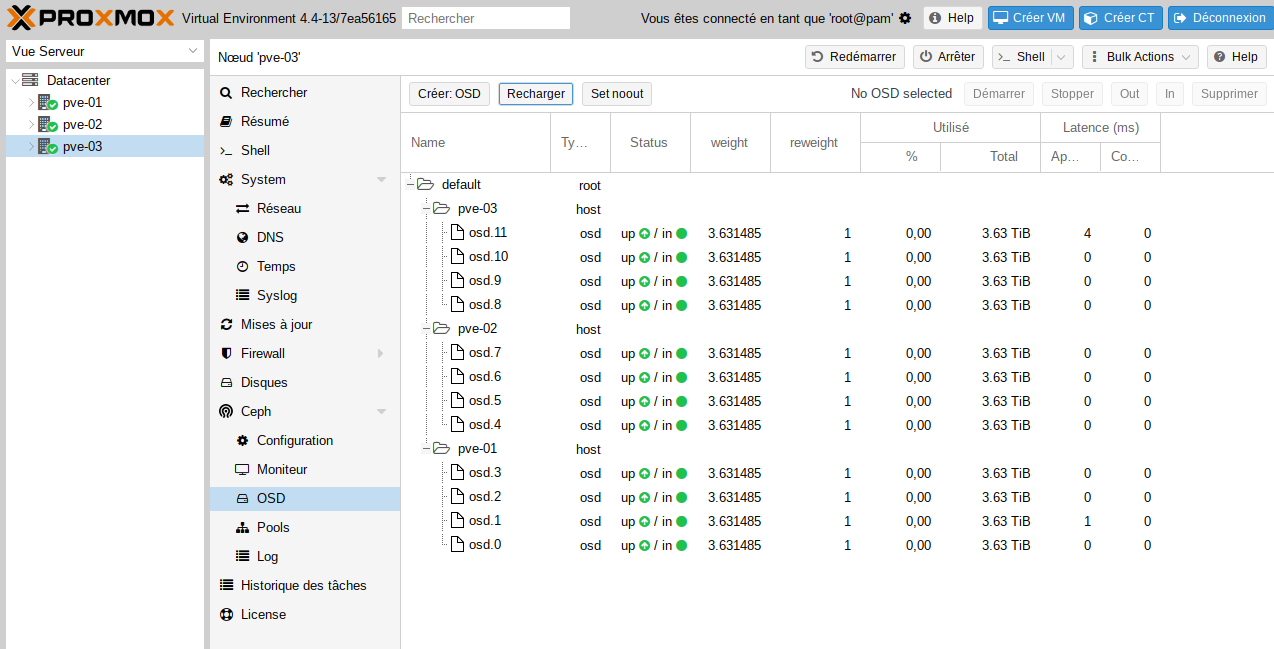
b/ Création du pool
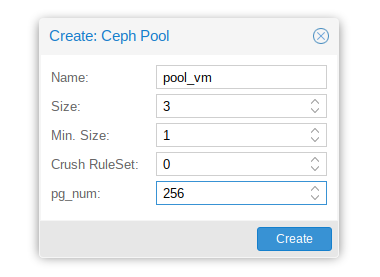
Avant de créer un nouveau pool, il faut calculer le pg_num.
- Calcul du pg_num :
(OSDx100)/size -> choisir la puissance de 2 supérieur au résultat de l’opération.
OSD : nombre total d’OSD choisi pour le pool
size : nombre de réplication- Exemple pour mon nouveau pool :
(4*100)/3 = 133.33- mon pg_num sera de une puissance de 2 supérieur à 133, c’est à dire dans mon cas : 256
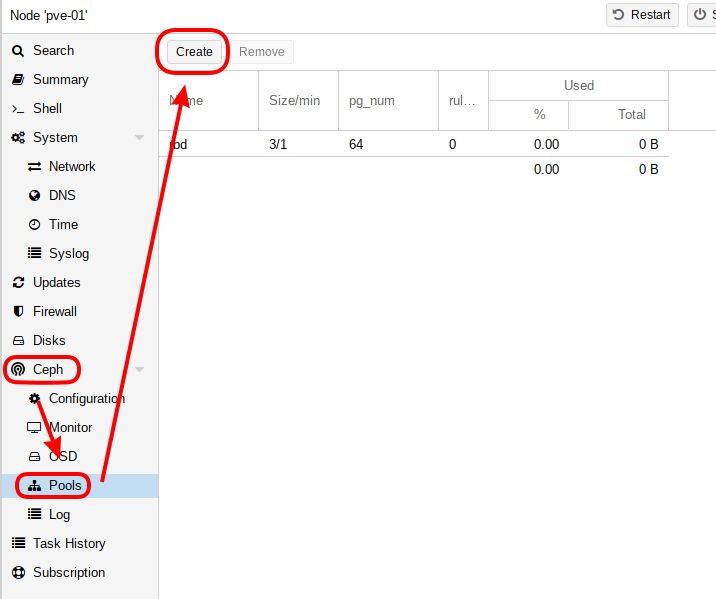
- Aller dans le menu « Ceph » puis « Pools » et cliquer sur « Create » :
- Remplir les champs :
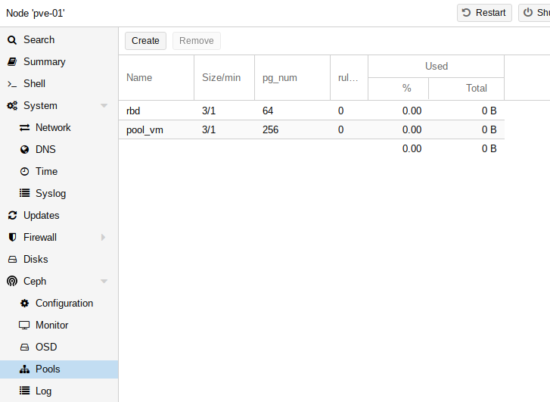
- Le nouveau Pool créé :
- Exemple pour mon nouveau pool :

c/ Ajout du nouveau stockage Ceph aux nœuds proxmox
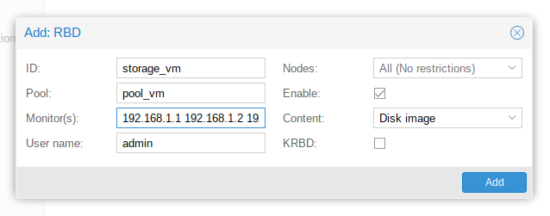
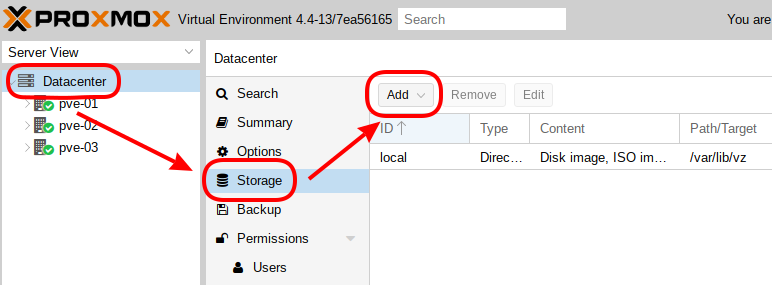
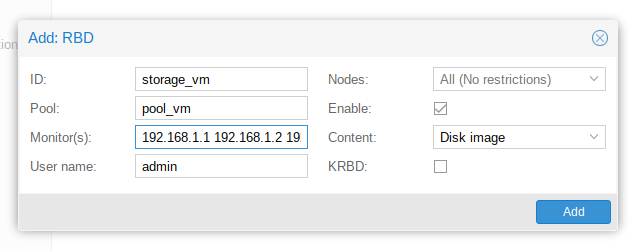
- Aller dans « Datacenter », puis menu « Storage » et cliquer sur « Add » :
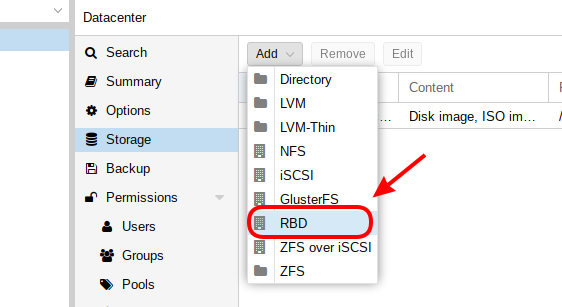
- Choisir le type de stockage RDB :
- Renseigner les champs :
- ID : donner un nom au nouveau stockage
- Pool : sélectionner le pool créé précédemment
- Monitor(s) : ajouter les adresses Ip des monitors
- User name : laisser admin
- Nodes : laisser All
- Enable : laisser coché
- Centent : Disk Image
- KRBD : ne pas cocher (c’est pour LXC)
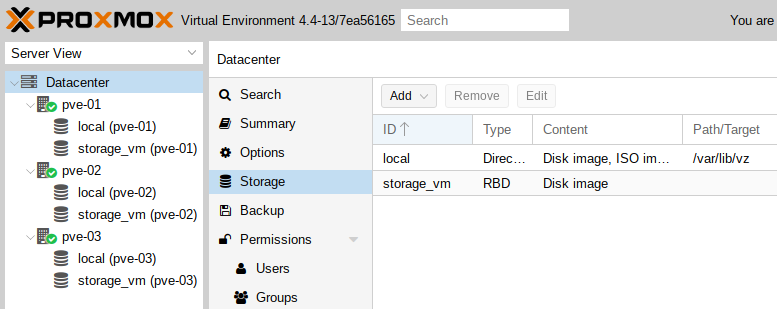
- Le nouveau stockage Ceph créé sur tous les nœuds du cluster proxmox :
- Autorisation d’accès au nouveau stockage à partir des nœuds du cluster :
mkdir /etc/pve/priv/ceph cp /etc/ceph/ceph.client.admin.keyring /etc/pve/priv/ceph/storage_vm.keyring
nb : le nom storage_vm est identifié dans le fichier /etc/pve/storage.cfg
d/ Fin de la première méthode me la mise en place de la solution de stockage distribuée Ceph sur un cluster Proxmox
Fin de la première méthode pour créer un cluster HA avec du stockage distribué Ceph, qui est la méthode la plus simple et fortement conseillé d’utiliser car gérée entièrement par Proxmox.
Cluster Ceph avec 2 pools créé en ligne de commande
Attention, ce qui suit ne sera plus géré par l’interface web de Proxmox !
- 3 Serveurs Dell R730 pour les Proxmox, avec :
- 2 disques 146 Go SAS 15K RAID1 pour PVE + Monitor
- 3 disques 300 GO SAS 15K : 2 OSD + 1 journalisation
- 3 disques 4 TO SATA 7.4K pour OSD
- Schéma réseau simplifié du cluster HA :
a/ Création des OSD
Chaque disque est configuré en RAID 0.
- Sur chaque nœud :
- Le premier disque dédié à la journalisation :
pveceph createosd /dev/sdb -journal_dev /dev/sdb
- Créer les OSD avec les disques restant :
pveceph createosd /dev/sd[X]
- Sur chaque nœud :

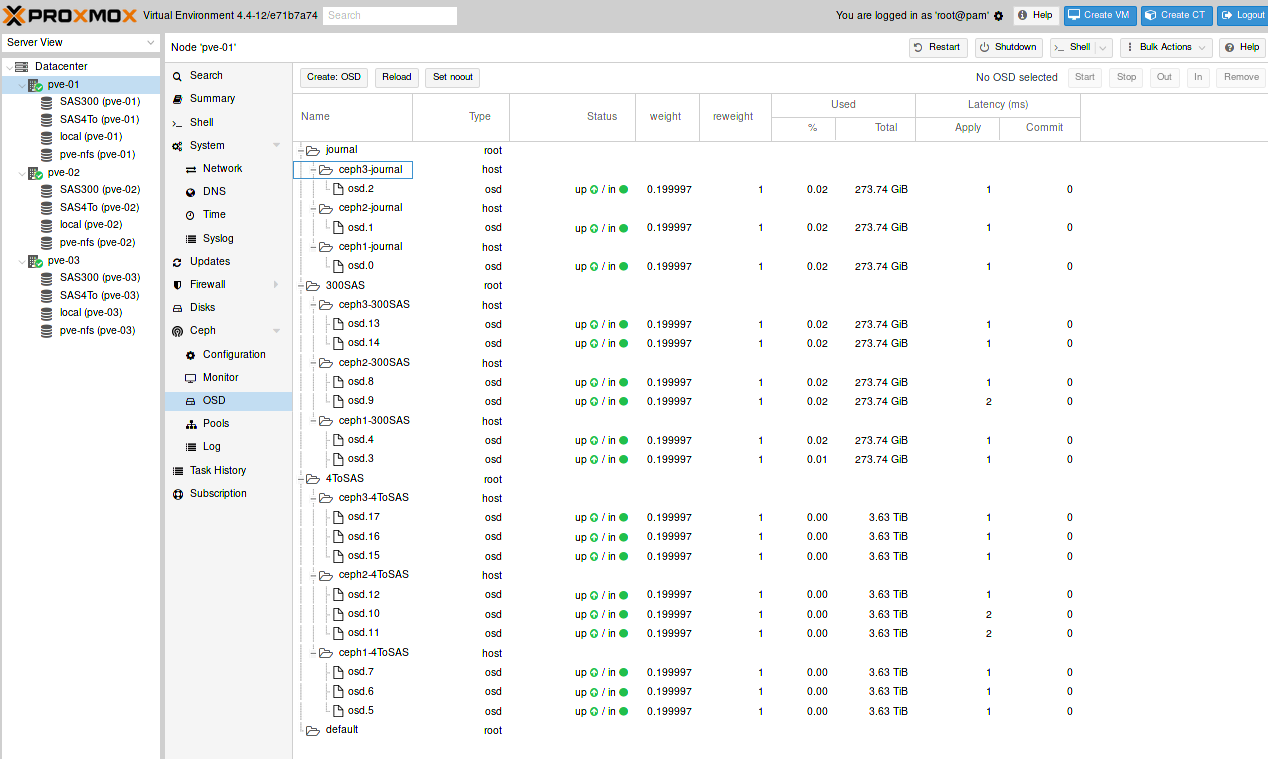
b/ Personnalisation du Crush MAP
La Crush MAP permet de déterminer comment vont être utilisés chaque OSD. Mon but est de regrouper les disques de 300Go ensemble et idem pour ceux de 4To.
- Création des root :
ceph osd crush add-bucket 300SAS root ceph osd crush add-bucket 4ToSAS root ceph osd crush add-bucket journal root
ceph osd crush add-bucket ceph1-300SAS host ceph osd crush add-bucket ceph2-300SAS host ceph osd crush add-bucket ceph3-300SAS host
ceph osd crush add-bucket ceph1-4ToSAS host ceph osd crush add-bucket ceph2-4ToSAS host ceph osd crush add-bucket ceph3-4ToSAS host
ceph osd crush add-bucket ceph1-journal host ceph osd crush add-bucket ceph2-journal host ceph osd crush add-bucket ceph3-journal host
ceph osd crush move ceph1-journal root=journal ceph osd crush move ceph2-journal root=journal ceph osd crush move ceph3-journal root=journal
ceph osd crush move ceph1-300SAS root=300SAS ceph osd crush move ceph2-300SAS root=300SAS ceph osd crush move ceph3-300SAS root=300SAS
ceph osd crush move ceph1-4ToSAS root=4ToSAS ceph osd crush move ceph2-4ToSAS root=4ToSAS ceph osd crush move ceph3-4ToSAS root=4ToSAS
Pour lister les OSDs :
ceph osd tree
ceph osd crush add osd.0 0.200 host=ceph1-journal ceph osd crush set osd.0 0.2 root=journal host=ceph1-journal ceph osd crush add osd.1 0.200 host=ceph2-journal ceph osd crush set osd.1 0.2 root=journal host=ceph2-journal ceph osd crush add osd.2 0.200 host=ceph3-journal ceph osd crush set osd.2 0.2 root=journal host=ceph3-journal
ceph osd crush rm osd.0 pve-01 ceph osd crush rm osd.1 pve-02 ceph osd crush rm osd.2 pve-03
ceph osd crush rm pve-01 ceph osd crush rm pve-02 ceph osd crush rm pve-03
Les OSD sont maintenant répartis de cette manière :
- Dans
/etc/pve/ceph.confajouter dans la section [osd] :
osd crush update on start = false
c/ Création des Pools
- Calcul du pg_num :
(OSDx100)/size -> choisir la puissance de 2 supérieur au résultat de l’opération.
OSD : nombre total d’OSD choisi pour le pool
size : nombre de réplication- Exemple pour mon pool de 300SAS :
(6*100)/3 = 200- mon pg_num sera de une puissance de 2 supérieur à 200, c’est à dire dans mon cas : 256
- Pour mon pool de 4ToSAS :
(9*100)/3 = 300- Mon pg_num pour mon pool de 4To SAS est de 512
- Exemple pour mon pool de 300SAS :
- Un pool avec les disques 300Go :
pveceph createpool 300SAS -min_size 1 -pg_num 256 -size 3 -crush_ruleset 1
pveceph createpool 4ToSAS -min_size 1 -pg_num 512 -size 3 -crush_ruleset 2
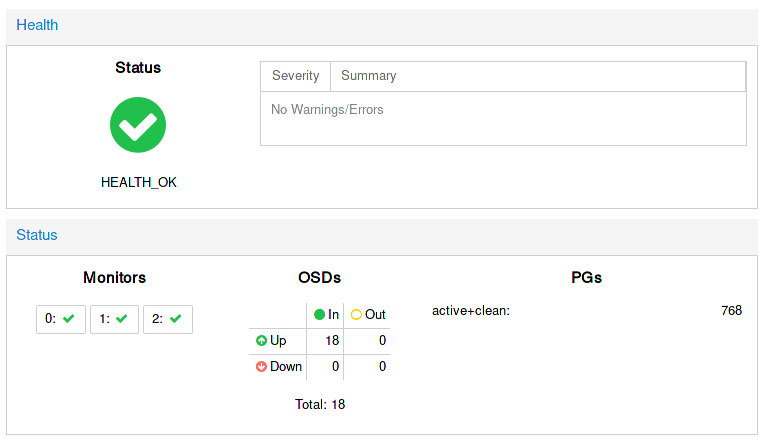
ceph -s
cluster 154458fd-6c1b-4573-adfc-e87357ca13ca
health HEALTH_OK
monmap e3: 3 mons at {0=192.168.1.1:6789/0,1=192.168.1.2:6789/0,2=192.168.1.3:6789/0}
election epoch 66, quorum 0,1,2 0,1,2
osdmap e771: 18 osds: 18 up, 18 in
flags sortbitwise,require_jewel_osds
pgmap v27046: 768 pgs, 2 pools, 0 bytes data, 0 objects
1008 MB used, 35930 GB / 35931 GB avail
768 active+clean
ou via l’interface web de Proxmox :
d/ Ajout du stockage Ceph pour les noeuds Proxmox
- Menu Stockage, cliquer sur « Add » puis choisir RDB :
- Renseigner les champs :
- ID : donner un nom au nouveau stockage
- Pool : choisir le bon pool
- Monitor(s)s : renseigner les adresses Ip de chaque noeuds séparées d’un espace
- User name : laisser admin
- Les nouveaux stockages sont disponibles pour chaque nœud :
- Pour avoir les autorisations d’accès, créer un fichier de clé pour chaque nouveau stokage RBD :

mkdir /etc/pve/priv/ceph cp /etc/ceph/ceph.client.admin.keyring /etc/pve/priv/ceph/SAS300.keyring cp /etc/ceph/ceph.client.admin.keyring /etc/pve/priv/ceph/SAS4To.keyring
e/ Fin de la première méthode me la mise en place de la deuxième solution de stockage distribuée Ceph sur un cluster Proxmox
Fin de la deuxième méthode. Je rappel attention avec cette méthode car toute la gestion du ceph se fait en ligne de commande. Cependant, cette méthode permet de comprendre un peu plus le fonctionnement et le paramétrage de Ceph.
Configuration du minuteur Watchdog matériel
Sous Proxmox 4.x il n’est plus nécessaire de configurer le fencing car il est pris en charge directement par Proxmox. Cependant, la gestion est au niveau logiciel et je souhaite qu’elle soit au niveau matériel. Dans ce cas, je vais utliser l’utilitaire de la carte iDRAC :
Vérification des valeurs actuelles
- Installation de l’outil idracadm7 :
apt install srvadmin-idracadm7
idracadm7 getsysinfo -w
Watchdog Information: Recovery Action = None Present countdown value = 479 seconds Initial countdown value = 480 seconds
Les valeurs par défaut sont trop hautes et aucune action de définie.
Configuration du Watchdog à 10secondes
- Editer le fichier
/etc/default/pve-ha-managerpour activer watchdog :
nano /etc/default/pve-ha-manager
# select watchdog module (default is softdog) WATCHDOG_MODULE=ipmi_watchdog
- Éditer
/etc/default/grub:
nano /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT :GRUB_CMDLINE_LINUX_DEFAULT="quiet nmi_watchdog=0"
update-grub

/opt/dell/srvadmin/sbin/dcecfg command=removepopalias aliasname=dcifru
reboot
idracadm7 getsysinfo -w
Watchdog Information: Recovery Action = Reboot Present countdown value = 9 seconds Initial countdown value = 10 seconds
Un peu de tuning
- Accélérer la migration des machines virtuelles :
- Renseigner l’utilisation du réseau privé pour la migration des VMs à chaud dans le fichier
/etc/pve/datacenter.cfgen ajoutant :migration: insecure,network=192.168.1.0/24
- Relancer les services :
systemctl restart pve-cluster systemctl restart pvedaemon systemctl restart pvestatd systemctl restart pveproxy
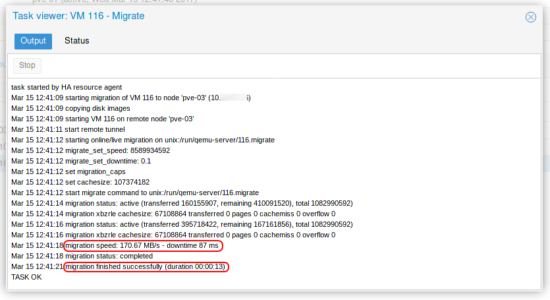
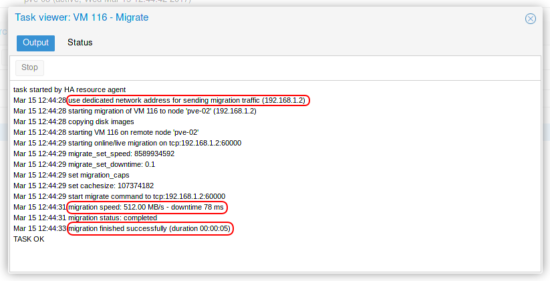
- Résultat d’une migration à chaud d’une VM :
- Avant modification :
- Après modification :
- Renseigner l’utilisation du réseau privé pour la migration des VMs à chaud dans le fichier

Ressources
- La documentation officielle de Proxmox : https://pve.proxmox.com/wiki/Ceph_Server
- Pour la personnalisation de la Crush Map : http://www.jaxlug.net/index.php/2014/07/16

Impressionant et merci pour le partage, avez vous fait ensuite des batteries de tests en provoquant des pannes artificielles ?
Pas encore mais c’est prévu dans les prochains jours… J’écrirais un article sur ce sujet…
Bonjour, et bravo pour ce tuto des plus intéressant et formateur.
Après l’avoir suivi je suis confronté à un problème(J’ai dû louper quelque chose.).
J’ai bien mes OSD réparti mais Proxmox m’indique qu’il ne peu résoudre ceph1-300SAS ou ceph1-4ToSAS
Pouvez vous ajouter le contenu du fichier /etc/pve/ceph.conf ?
Avez vous ajouter des alias au niveau des hosts ?
J’espère avoir clairement exposé mon problème.
Encore bravo et merci d’avance de vous pencher sur ma question.
Bonjour j.esnault,
voici mon /etc/pve/ceph.conf
[global]
auth client required = cephx
auth cluster required = cephx
auth service required = cephx
cluster network = 192.168.1.0/24
filestore xattr use omap = true
fsid = 154458fd-6c1b-4573-adfc-e87357ca13ca
keyring = /etc/pve/priv/$cluster.$name.keyring
osd journal size = 5120
osd pool default min size = 1
public network = 192.168.1.0/24
[osd]
keyring = /var/lib/ceph/osd/ceph-$id/keyring
osd crush update on start = false
[mon.2]
host = pve-03
mon addr = 192.168.1.3:6789
[mon.1]
host = pve-02
mon addr = 192.168.1.2:6789
[mon.0]
host = pve-01
mon addr = 192.168.1.1:6789
J’avais rencontré ce problème de non résolution des hosts mais je n’ai plus souvenir du pourquoi et comment j’avais résolu ce problème…
Alors attention, il y a plus simple pour Ceph, c’est d’avoir qu’un seul poole le tout géré par proxmox, mon architecture de Ceph est un peu complexe…
Bonjour,
Bravo et merci pour cette super doc. Une question svp :
Pourquoi avoir passé le fencing du mode logiciel au mode matériel ?
Quel en est l’intérêt ? Et surtout, peut-on s’en passer ? J’ai en effet une supervison matérielle de type centreon sur les cartes IDRAC, et je crains que la modification de ses paramètres (par défaut) pour utiliser watchdog ne perturbe la supervision…
Bonjour,
pour tout ce qui touche au management matériel, je préfère passer par la carte iDrac. Je supervise aussi mes serveurs avec Centreon et aucun souci :-)
Bonjour,
Merci pour ce post.
Avez-vous tester Ceph avec Proxmox VE 5?
J’ai systématiquement une erreur avec l’initialisation du pool ceph: mon_command failed – unrecognized variable ‘crush_ruleset’ (500). Le pool est ensuite créé mais impossible de s’y connecter.
Merci
Bonjour Kevin,
j’ai migré mon cluster Proxmox 4 vers 5 mais pas d’installation encore à partir de la version 5 (prévue courant Aout)
Le pool Ceph est-il créé via l’interface web ou via la ligne de comande ? à priorie, vue le message il y a une erreur de variable non reconnue… peut être changé le nom du pool…
Bonjour,
Tout cela m’a l’air très clair mais je ne comprend pas comment les disques sont mappés correctement surbons pools (SATA vs SSD) ? Je vois que sont utilisées des ruleset mais n’y a t-il pas un besoin de les definir pour justement spécifier quel root ils utilisent ? Ou j’ai rien compris :)
Bonjour, Vous devez modifier la crushmap. Definir « simuler » des hosts contenant des ssd ou hdd, puis creer de nouveau « root » section.
voir : https://www.sebastien-han.fr/blog/2014/08/25/ceph-mix-sata-and-ssd-within-the-same-box/
Bon courage
Bonjour Fred, super tes tutos un peu hard pour les newbies comme moi….
J’aimerai quelle précision pour voir si j’ai bien compris.
Ton pool SAS4To te sert bien pour stocker tes données ?
Ton pool SAS300 te sert bien pour stocker tes VM ?
A quoi sert celui pour la journalisation exactement ?
Pourquoi à tu choisi RDB ?
Ce que je n’ai pas compris c’est quant tu dis que Chaque disque est configuré en RAID 0. Et que tu as 4 OSD pour tes 4 disque de 4To ce n’est donc pas un RAID Matériel ? Je patauge un peu ou alors c’est peut être la subtilité entre les deux méthodes.
J’ai quasi la même config que toi mis a part les disques, quelle méthode me conseille tu ? En cas de crache d’un disque la quelle est la plus simple a remettre en état.
Je suis sur proxmox 5.1.
Encore Bravo.
PS Merci pour ton script post install .
Pour info il ne fonctionne pas directement il faut reprendre les » par » et ‘,’ par ‘
Encore un dernière
le ligne echo « deb http://linux.dell.com/repo/community/debian jessie openmanage » > /etc/apt/sources.list.d/linux.dell.com.sources.list est elle nécéssaire ou contre productive avec 5.1 sous stretch ?
Bonjour AlexisD,
oui cet article est un peu hard faut l’avouer :-)
je te conseil de partir sur 1 seul pool car c’est plus simple à mettre en œuvre et point de vue Proxmox c’est plus propre.
Concernant les RAID 0, c’est une étape qui n’est pas du tout obligatoire en faite, cela dépend de ta carte RAID. Je n’avais pas sût comment faire « voir » mes disques au système sans passer par l’étape du RAID (solution de simplicité dans mon cas).
Les disques appartenant au pool CEPH sont entièrement géré par le CEPH et non par le RAID.
Faut que je mettre à jour mon script de post-installation pour la version 5 de Proxmox, j’avais commencé mais pas terminé (je dois avoir une version propre sur mon PC du bureau).
Pour le dépôt Openmanage voir cet article : https://memo-linux.com/installer-openmanage-9-0-1-sur-debian-9-et-ubuntu-16-04/
Faut que je planifie la mise à jour de cet article pour Proxmox 5…
Bonjour fred,
Pour quelle raison Proxmox ne peut plus gérer le Ceph une fois qu’on l’a géré à la main ?
Cordialement