Lorsqu’on déploie un cluster Ceph, il est essentiel de comprendre les performances du ou des pools. Que ce soit pour des VMs, du stockage objet ou du backup, mesurer le débit, les IOPS et la latence permet d’identifier les goulots d’étranglement et d’optimiser la configuration.
Comment créer un benchmark d’un pool Ceph sur Proxmox et automatiser le test
Ce mémo explique comment réaliser un benchmark d’un pool Ceph de manière sécurisée et comment automatiser cette opération avec un script Bash.
Préparation du pool
Pour éviter de perturber les VMs ou les données, créer un pool temporaire dédié au test :
ceph osd pool create pool_test 128- 128 correspond au nombre de placement groups (PG), à ajuster selon la taille de votre cluster.
- Ce pool servira uniquement pour le benchmark.
2. Comprendre les métriques de rados bench
rados bench est l’outil de référence pour tester un pool Ceph. Voici ce qu’il mesure :
- Write (MB/s) : débit d’écriture séquentielle sur le pool.
- Seq Read (MB/s) : débit de lecture séquentielle.
- Rand Read (IOPS) : nombre d’opérations d’E/S aléatoires par seconde.
- Latency (ms) : latence moyenne des opérations.
Exemple de commande :
rados bench 60 write -p pool_test -t 16 -b 4M- 60 : durée du test en secondes
- -t 16 : nombre de threads concurrents
- -b 4M : taille des blocs pour l’écriture
Benchmark sécurisé et manuel
Pour éviter de toucher aux VMs :
- Créer un objet test dans le pool temporaire.
- Faire un write bench sur cet objet.
- Enchaîner avec un seq read et un rand read pour mesurer le débit et les IOPS.
- Supprimer les objets test après le benchmark avec
rados cleanup.
Cette méthode garantit que les données existantes ne sont jamais affectées.
Automatiser le benchmark avec un script
Répéter ces tests manuellement est fastidieux. Pour gagner du temps et obtenir des résultats uniformes et faciles à comparer, je vous propose ce script :
wget https://raw.githubusercontent.com/freddL/benchmark_pool_ceph/main/benchmark_pool_ceph.sh -O benchmark_pool_ceph.sh chmod +x benchmark_pool_ceph.sh ./benchmark_pool_ceph.sh
Fonctionnalités du script
- Crée un pool temporaire pour le benchmark.
- Effectue write, seq read et rand read automatiquement.
- Parse les résultats pour afficher débit, latence et IOPS.
- Affiche un tableau clair et lisible dans le terminal.
- Nettoie automatiquement le pool temporaire ou demande confirmation avant suppression.
- Paramètres configurables : durée, threads, taille des blocs, nombre de PG.
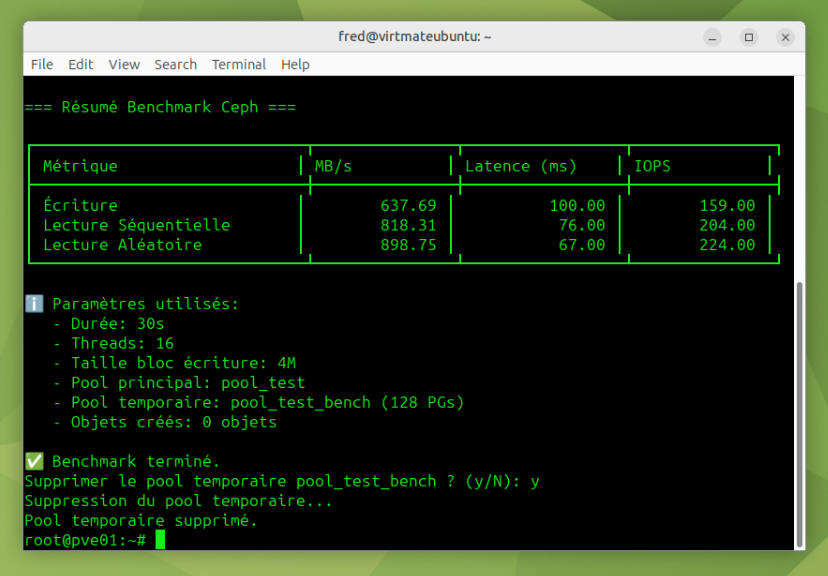
Extrait de la sortie :
┌─────────────────────────────┬───────────────┬─────────────────┬───────────────┐
│ Métrique │ MB/s │ Latence (ms) │ IOPS │
├─────────────────────────────┼───────────────┼─────────────────┼───────────────┤
│ Écriture │ 615.91 │ 0.10 │ 153 │
│ Lecture Séquentielle │ 412.34 │ 0.08 │ 98 │
│ Lecture Aléatoire │ 125.67 │ 0.12 │ 205 │
└─────────────────────────────┴───────────────┴─────────────────┴───────────────┘Interprétation des Résultats du Benchmark Ceph
1. Écriture (Write)
MB/s élevé + Latence faible :
- Signification : Votre pool Ceph est optimisé pour les opérations d’écriture rapides, ce qui est idéal pour les machines virtuelles (VM).
- Pourquoi ?
- Les VM nécessitent des écritures rapides pour les opérations comme l’installation de logiciels, la création/modification de fichiers, ou les logs.
- Une latence faible garantit que les VM ne subissent pas de ralentissements lors des écritures sur le stockage.
2. Lecture Séquentielle (Seq Read)
MB/s élevé :
- Signification : Votre pool est performant pour les lectures séquentielles, ce qui est parfait pour le streaming (vidéo, audio) ou les backups.
- Pourquoi ?
- Le streaming lit les données de manière séquentielle (ex. : lecture d’un film ou d’une sauvegarde).
- Un débit élevé en lecture séquentielle assure une lecture fluide sans buffering.
3. Lecture Aléatoire (Rand Read) / IOPS
IOPS élevé + Latence faible :
- Signification : Votre pool est optimisé pour les accès aléatoires, ce qui est critique pour les bases de données (MySQL, PostgreSQL, etc.) ou les applications transactionnelles (ex. : ERP, CRM).
- Pourquoi ?
- Les bases de données effectuent des lectures/écritures aléatoires fréquentes (ex. : requêtes SQL).
- Un nombre élevé d’IOPS garantit que les requêtes sont traitées rapidement, sans goulot d’étranglement.
Résumé des Cas d’Usage
| Type de Benchmark | Métrique Clé | Cas d’Usage Idéal |
|---|---|---|
| Écriture (Write) | MB/s élevé, Latence faible | Machines virtuelles (VM), logs, fichiers. |
| Lecture Séquentielle | MB/s élevé | Streaming (vidéo, audio), backups. |
| Lecture Aléatoire (IOPS) | IOPS élevé, Latence faible | Bases de données, applications transactionnelles. |
Exemple Pratique
Si vos résultats montrent :
- Écriture : 500 MB/s, Latence = 5 ms → Bon pour les VM.
- Lecture Séquentielle : 800 MB/s → Idéal pour le streaming.
- Lecture Aléatoire : 10 000 IOPS, Latence = 2 ms → Parfait pour les bases de données.
Que faire si les performances sont insuffisantes ?
- Écriture lente :
- Vérifiez la configuration des OSDs (disques, réseau).
- Augmentez le nombre d’OSDs ou utilisez des SSD pour le tiering.
- Lecture séquentielle faible :
- Optimisez la taille des blocs (BLOCK_READ) pour le streaming.
- Utilisez des disques à haut débit (ex. : NVMe).
- IOPS faibles en lecture aléatoire :
- Ajoutez plus d’OSDs ou utilisez des SSD pour réduire la latence.
- Vérifiez la configuration du réseau (latence, bande passante).