Un mémo sur comment créer un cluster de haute disponibilité de deux serveurs avec corosync et pacemaker.
Dans mon cas, les deux serveurs ont un rôle de par-feux (firewall) gérant plusieurs VLAN. La distribution utilisée est Ubuntu serveur 16.04LTS.
Étant donné, que les serveurs ont un rôle de firwewall, je souhaite bénéficier de la haute disponibilité en cas d’une défaillance sur le serveur actif afin d’avoir de la continuité de service. Les liens Ethernet de chaque vlan sont doublés, agrégés (bonding) et dispatchés vers deux commutateur configurés en pile.
Installation et configuration du cluster HA avec corosync et pacemaker
- Schéma de principe du cluster HA :
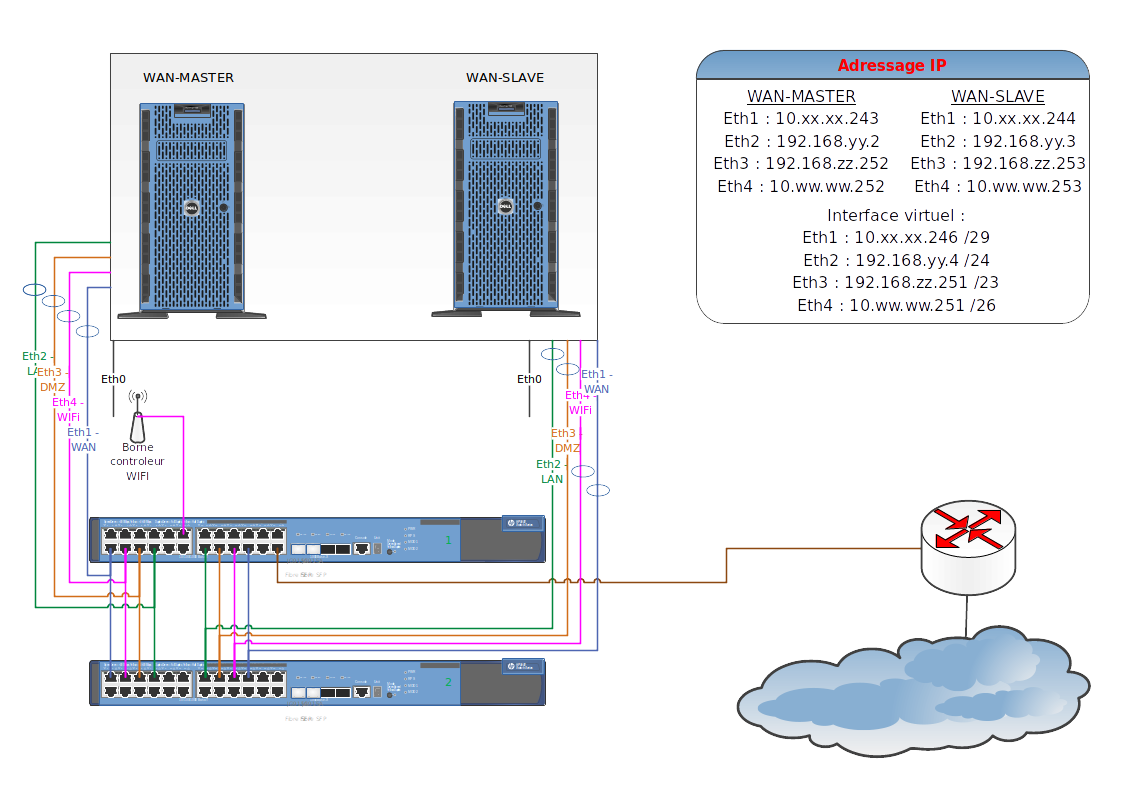
Dans cet article, la configuration du firewall, de l’agrégation des liens, la mise en pile des commutateurs et la configuration des ports ne seront pas traitées.
Installation du cluster
- Mise à jour du système :
apt update && apt full-upgrade
apt install pacemaker corosync crmsh
Configuration du cluster HA
- Modifier le fichiers hosts des deux serveurs :
nano /etc/hosts
10.xx.xx.243 wan-master 10.xx.xx.244 wan-slave
iptables -I INPUT -m state --state NEW -p udp -m multiport --dports 5404,5405 -j ACCEPT iptables -I OUTPUT -m state --state NEW -p udp -m multiport --sports 5404,5405 -j ACCEPT
corosync-keygen
scp /etc/corosync/authkey root@wan-slave:/etc/corosync/
mv /etc/corosync/corosync.conf /etc/corosync/corosync.back
nano /etc/corosync/corosync.conf
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: wan-master
nodeid: 1
quorum_votes: 1
ring0_addr: 10.xx.xx.243
}
node {
name: wan-slave
nodeid: 2
quorum_votes: 1
ring0_addr: 10.xx.xx.244
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
totem {
cluster_name: cluster-ha
config_version: 3
ip_version: ipv4
secauth: on
version: 2
interface {
bindnetaddr: 10.xx.xx.243
ringnumber: 0
}
}
scp /etc/corosync/corosync.conf root@wan-slave:/etc/corosync/
- stonith « shot the other node in the head » permet lorsqu’une machine n’est plus joignable d’être sur que cette machine soit bien hors ligne mais nécessite la gestion du fencing (gestion matériel avec par exemple ipmi).
crm configure property stonith-enabled=false
crm configure property no-quorum-policy=ignore
systemctl start corosync systemctl start pacemaker
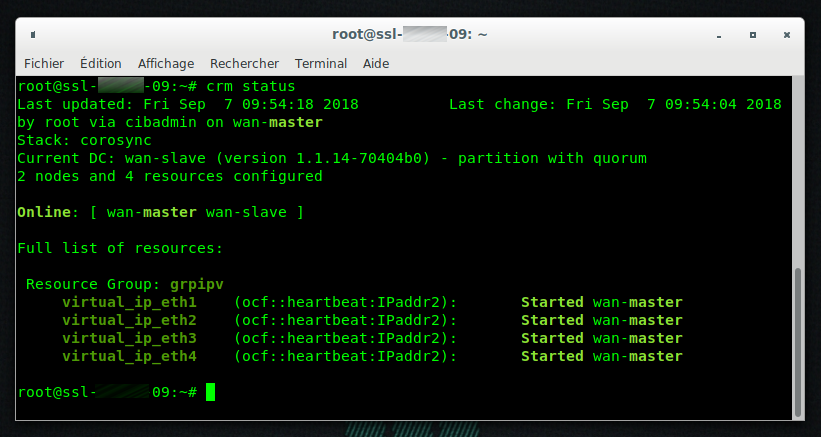
crm status

crm configure primitive virtual_ip_eth1 ocf:heartbeat:IPaddr2 params ip="10.xx.xx.246" cidr_netmask="29" nic="bond0" op monitor interval="10s" timeout="20" meta failure-timeout="5"
crm configure primitive virtual_ip_eth2 ocf:heartbeat:IPaddr2 params ip="E192.168.yy.4" cidr_netmask="24" nic="bond1" op monitor interval="10s" timeout="20" meta failure-timeout="5"
crm configure primitive virtual_ip_eth3 ocf:heartbeat:IPaddr2 params ip="192.168.zz.251" cidr_netmask="23" nic="bond2" op monitor interval="10s" timeout="20" meta failure-timeout="5"
crm configure primitive virtual_ip_eth4 ocf:heartbeat:IPaddr2 params ip="10.ww.ww.251" cidr_netmask="26" nic="bond3" op monitor interval="10s" timeout="20" meta failure-timeout="5"
crm configure group grpipv virtual_ip_eth1 virtual_ip_eth2 virtual_ip_eth3 virtual_ip_eth4
crm configure location grpipv-location grpipv 50: wan-master
crm status
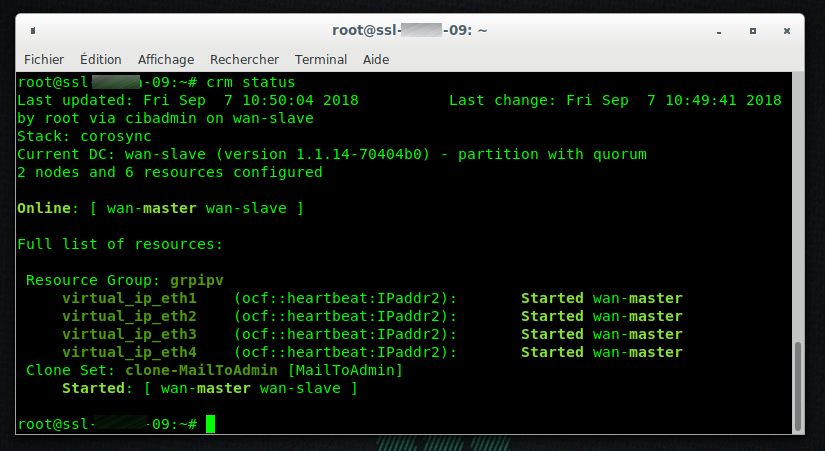
Ajouter des services au cluster
Dans mon cas, je ne vais ajouter qu’un seul service, l’envoie de mail lors d’un basculement d’état des serveurs :
- Ajout alerte mail :
crm configure primitive MailToAdmin ocf:heartbeat:MailTo params email=admin@domaine.tld op monitor depth="0" timeout="10" interval="10"
crm configure clone clone-MailToAdmin MailToAdmin
crm status
Monitorer l’état du branchement du câble réseau sur la carte Ethernet
Par défaut (bug ?), pacemaker de prend pas en charge le débranchement/coupure du câble réseau sur l’interface.
- Éditer le module IPaddr2 :
nano /usr/lib/ocf/resource.d/heartbeat/IPaddr2
{
t=$(ip link show "$NIC" | grep -c "state UP")
if [ "$t" = "0" ];then
return "$OCF_ERR_PERM"
else
return "$OCF_SUCCESS"
fi
}
Quelques commandes utiles
- Lister tous les modules disponibles :
crm ra list ocf
crm status
crm configure show
crm resource stop nom-de-la-ressource
crm configure delete nom-de-la-ressource
crm resource cleanup nom-de-la-ressource
crm node standby wan-master
crm node online wan-master
Ressources
- La bible sur corosync et pacemaker : https://clusterlabs.org/
- Pour corriger le bug, je me suis inspiré de : https://oss.clusterlabs.org/pipermail/pacemaker/2012-June/014596.html

Bonjour,
Merci pour cette présentation
Quel est l’avantage de cette solution par rapport à l’utilisation de KeepAlived ?
Bonjour Fabien,
je n’ai pas encore testé KeepAlived, je ne peux donc pas faire de comparatif
Où comment faire compliqué avec Linux quand on peut faire simple ;)
Une solution adaptée est l’utilisation d’un cluster CARP avec OpenBSD.
Hello Fred,
Merci pour ton travail. Je viens de m’en inspirer pour monter un cluster HA pour du 3CX. Toutefois je bloque sur mon « resource group » qui reste en « stopped ». Après investigation, j’ai l’impression que mon problème vient de fait que je n’ai pas d’aggréga « bond0 » sur mes serveurs uniquement des interfaces.
Il y a moyen que tu nou montre ton fichier /etc/network/interfaces s’il te plaît???
Après faut cacher les IP ;-)
Merci d’avance
Très bon article, merci à vous. Par contre utiliser cette solution avec PCS et vous avez un outil clé en main qui permet d’éviter d’aller mettre les mains dans les fichiers conf et/ou xml. PCS marche plutot pas mal maintenant avec les distribs debian.
avec seulement 2 nodes, il faut vraiment vraiment utiliser l’option « two_node: 1 » autrement vous vous exposez à pleins de corner cases :
quorum {
provider: corosync_votequorum
two_node: 1
}
merci Julien,
je l’ajoute dans l’article